Minule jsme si ukรกzali jednoduchรฝ plรกn, kterรฝ byl vytvoลen pลรญmo v reลพii Query Optimizeru. Pลi psanรญ komplexnฤjลกรญch dotazลฏ si urฤitฤ budete chtรญt testovat rychlost jejich bฤhu. Jinรฝmi slovy budete se zajรญmat o to, jak se zmฤnรญ rychlost zpracovรกnรญ dotazu, kdyลพ napล. pลidรกte, smaลพete, zmฤnรญte index nad tabulkou, vynutรญte parametrizaci dotazu, atp. Prรกvฤ k laborovรกnรญ a zkouลกenรญ se vรฝbornฤ hodรญ moลพnost pลesvฤdฤit Query Optimizer, aby vytvoลil plรกn trochu jinak.
Ukรกzka pลฏvodnรญho dotazu, kterรฝ budeme postupnฤ modifikovat a vynucovat si zmฤny vรฝslednรฉho plรกnu
SELECT P.LastName ,P.FirstName ,E.EmailAddress FROM Person.Person AS P LEFT JOIN Person.EmailAddress AS E ON E.BusinessEntityID = P.BusinessEntityID WHERE P.LastName = 'Smith'
Originรกlnรญ plรกn vypadรก takto

Existuje nฤkolik zpลฏsobลฏ, jakรฝmi Optimizer spojuje tabulky. Na vรฝลกe uvedenรฉm obrรกzku vidรญme Merge Join. Budeme-li chtรญt zmฤnit zpลฏsob spojenรญ tabulek, lze to provรฉst pomocรญ tzv. Join Hints.
Merge Join
Je pomฤrnฤ efektivnรญ spojenรญ dvou tabulek, mรกme-li na vstupu nejlรฉpe dvฤ setลรญdฤnรฉ sady dat, kterรฉ vลฏฤi sobฤ porovnรกvรกme a v pลรญpadฤ shody provedeme slouฤenรญ. V naลกem pลรญpadฤ chceme slouฤit informace z tabulky [Person].[Person] s informacemi z tabulky [Person].[EmailAddress]. Algoritmus tohoto spojenรญ vezme nejprve prvnรญ zรกznam ze setลรญdฤnรฉ tabulky [Person].[Person] a naฤte si hodnotu z pole [BusinessEntityID]. Vezme prvnรญ zรกznam z tabulky [Person].[EmailAddress], naฤte si hodnotu z pole [BusinessEntityID]. Pokud je hodnota pole [BusinessEntityID] v tabulce [Person].[EmailAddress] menลกรญ, naฤte se dalลกรญ zรกznam z tabulky [Person].[EmailAddress]. Takto se pokraฤuje, dokud hodnota [BusinessEntityID] nenรญ v obou tabulkรกch stejnรก. Rovnajรญ-li se hodnoty, jsou ลรกdky slouฤeny. Pokraฤuje se nรกsledujรญcรญm ลรกdkem z tabulky [Person].[EmailAddress], dokud hodnota pole [BusinessEntityID] v tabulce [Person].[EmailAddress] nenรญ vฤtลกรญ. Jakmile je vฤtลกรญ, znamenรก to, ลพe jiลพ neexistuje ลพรกdnรฝ dalลกรญ vyhovujรญcรญ zรกznam a pokraฤuje se novรฝm zรกznamem z [Person].[Person].
Dotaz, kterรฝm si vynutรญme pouลพitรญ Merge Join je nรกsledujรญcรญ
SELECT P.LastName ,P.FirstName ,E.EmailAddress FROM Person.Person AS P LEFT MERGE JOIN Person.EmailAddress AS E ON E.BusinessEntityID = P.BusinessEntityID WHERE P.LastName = 'Smith'
Vygenerovanรฝ plรกn naleznete na obrรกzku vรฝลกe.
Celkovรก nรกroฤnost dotazu pro porovnรกnรญ

Jak je patrnรฉ, plรกn upravenรฉho dotazu s pouลพitรญm MERGE JOIN je stejnรฝ jako pลฏvodnรญ plรกn, kterรฝ si Optimizer sestavรญ nativnฤ. Pro tento typ spojenรญ je limitujรญcรญm faktorem nutnรฉ setลรญdฤnรญ dat podle stejnรฝch kritรฉriรญ. Pokud je setลรญdฤnรญ dat pลรญliลก nรกkladnรฉ, pak je pouลพit jinรฝ typ.
Hash Join
Prvnรญm krokem je urฤenรญ poฤtu ลรกdkลฏ obou tabulek, kterรฉ jsou na vstupu tรฉto operace. Poฤet ลรกdkลฏ se urฤuje na zรกkladฤ statistik, kterรฉ v pลรญpadฤ jejich neaktuรกlnosti nemusรญ odpovรญdat realitฤ. Tabulka, kterรก obsahuje mรฉnฤ ลรกdkลฏ ([Person].[Person]), se nazรฝvรก build input a na jejรญm zรกkladฤ bude vytvoลena hash tabulka. Hash tabulku si mลฏลพeme pลedstavit jednoduลกe tak, ลพe se vezmou data z jednoho ฤi vรญce sloupcลฏ (zรกleลพรญ, kolik sloupcลฏ chceme porovnรกvat) a z dat se vytvoลรญ hash, kterรฝ se uloลพรญ do hash tabulky. Kaลพdรฉmu ลรกdku v hash tabulce tedy odpovรญdรก prรกvฤ jeden ลรกdek v originรกlnรญ tabulce. Je to jistรฉ zjednoduลกenรญ, kdy ve vรฝsledku porovnรกvรกme pouze jednu hodnotu v jednom sloupci z hash tabulky mรญsto hodnot v nฤkolika sloupcรญch v originรกlnรญ tabulce. Hash tabulka mลฏลพe bรฝt uloลพena pลรญmo v pamฤti v pลรญpadฤ relativnฤ malรฉ hash tabulky. Je-li nedostatek volnรฉ pamฤti, je uloลพena do TempDB. Mรกme tedy pลipravenou a naplnฤnou hash tabulku. Druhรก vฤtลกรญ tabulka na vstupu ([Person].[EmailAddress]) se nazรฝvรก probe input. Z vฤtลกรญ tabulky je postupnฤ ฤte ลรกdek po ลรกdku, z pลรญsluลกnรฝch sloupcลฏ poฤรญtรกn hash a porovnรกvรกn s hodnotami v hash tabulce. V pลรญpadฤ shody jsou ลรกdky poslรกny dรกle ke zpracovรกnรญ.
Dotaz, kterรฝm si vynutรญme pouลพitรญ Hash Join je nรกsledujรญcรญ
SELECT P.LastName ,P.FirstName ,E.EmailAddress FROM Person.Person AS P LEFT HASH JOIN Person.EmailAddress AS E ON E.BusinessEntityID = P.BusinessEntityID WHERE P.LastName = 'Smith'
Vygenerovanรฝ plรกn

Celkovรก nรกroฤnost dotazu pro porovnรกnรญ

Nested Loops Join
Jednรก se o mechanismus spojovรกnรญ dvou tabulek, kdy se prochรกzรญ zdrojovรก tabulka ลรกdek po ลรกdku a dohledรกvรก se odpovรญdajรญcรญ ลรกdky ve druhรฉ pลipojovanรฉ tabulce. Hornรญ vstup se oznaฤuje jako outer input. v naลกem pลรญkladฤ je to tabulka [Person].[Person]. V tabulce bylo nalezeno celkem 103 zรกznamลฏ s LastName = ‚Smith‘.

Spodnรญ tabulka ([Person].[EmailAddress]) je oznaฤovรกna jako inner input. Pro kaลพdรฝ ลรกdek outer input tabulky je prohledรกna celรก tabulka inner input, zda-li neexistujรญ ลรกdky odpovรญdajรญcรญ ลรกdku z outer input.

Na obrรกzcรญch si povลกimnฤte poฤet volรกnรญ (Actual Executions) pro outer a inner input. Z algoritmu je vidฤt, ลพe tento typ spojenรญ je vhodnรฝ pro dvฤ tabulky, z nichลพ jedna obsahuje mnohem mรฉnฤ ลรกdkลฏ neลพ druhรก a zรกroveล ve druhรฉ tabulce je index, kterรฝ pokrรฝvรก sloupce, podle nichลพ se filtruje.
Detail vlastnรญ Nested Loop operace je na nรกsledujรญcรญm obrรกzku

Dotaz, kterรฝm si vynutรญme pouลพitรญ Loop Join je nรกsledujรญcรญ
SELECT P.LastName ,P.FirstName ,E.EmailAddress FROM Person.Person AS P LEFT LOOP JOIN Person.EmailAddress AS E ON E.BusinessEntityID = P.BusinessEntityID WHERE P.LastName = 'Smith'
Vygenerovanรฝ plรกn

Celkovรก nรกroฤnost dotazu pro porovnรกnรญ
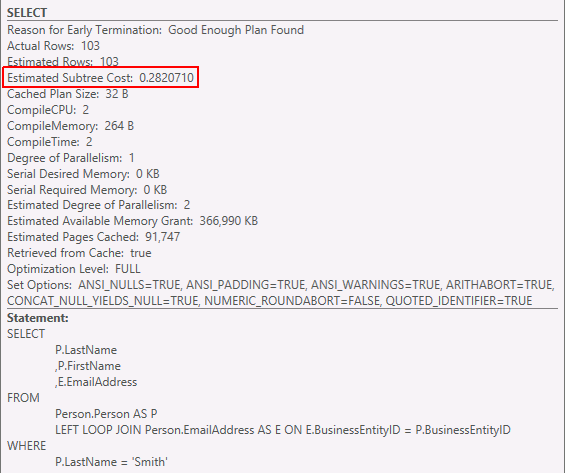
Porovnรกme-li celkovou nรกroฤnost jednotlivรฝch typลฏ spojenรญ tabulek, je vidฤt, ลพe nejmรฉnฤ nรกroฤnรฉ je spojenรญ typu Merge Join. Pลesnฤ to, kterรฉ si pลฏvodnฤ vybral Optimizer.